What I learned at the Deep Learning Summer School 2017 in Bilbao

Hey, what’s up guys? :-) I’m Vincenzo Lomonaco, 2nd year PhD student @ University of Bologna and today I’m gonna be following the advice and great example of Natalia Diaz Rodriguez, sharing my thoughts about the recent International Deep Learning Summer School 2017 which took place in Bilbao, Spain from the 17th to the 21th of July!
First of all I would like to congratulate the organizers who made this happen in Europe with any less quality than the “original” MILA Deep Leaning Summer School which has been advertised a bit late this year!
4 courses running in parallel for an entire week from 8 a.m to 8 p.m., open sessions, industrial sessions and most importantly more than than 1,300 great people coming from all over the globe! All placed in a beautiful city like Bilbao with welcoming people, great food… and a lot of amazing stuff to see!
But let’s stick to the main topic here! There were a lot of very high-profile speakers:
Li Deng, Richard Zemel, Richard Socher, Marc’Aurelio Ranzato, Maximilian Riesenhuber, George Cybenko, Jianfeng Gao, Michael Gschwind, Soo-Young Lee, Li Erran Li, Michael C. Mozer, Roderick Murray-Smith, Hermann Ney, Jose C. Principe …
Just to name a fews. Take a look at the complete list of speakers if you want to learn more about theirs talks/lectures.
Of course I could not follow all the talks and this post does not aim to be comprehensive anyhow of the entire event. I’d just like to share a few hints on what I personally valued most about the summer school.
What was the most useful thing you learned? I’d like to know what you think! please comment below :)
Li Deng — “Recent Advances in Unsupervised Deep Learning”
The fist talk and keynote of the conference was from Li Deng now working as Chief AI Officer at Citadel. I think he’s an amazing speaker other than one of the talented researchers who kick-started the entire wave of Deep Learning. He focused his talk on “Unsupervised Learning” and the way to achieve it, essentially by exploiting “inherent statistical structures of input and output” which most of the time means casting your problem in a sequence learning problem.
This idea has been around for a few time now, but the element of real originality stands in his recent line of works were he argues that more advanced optimization techniques (than plain SGD) may be needed for Unsupervised Learning and hence more complex loss surfaces [1][2].
Then he also gave a series of more basic but incredibly enriching lectures often interleaved with funny episodes and vivid historical moments which he directly experienced in his pivotal role in the resurgence of neural nets.

Richard Socher — “Tackling the Limits of Deep Learning”
The second keynote and great (even though remote) talk was from Richard Socher. I don’t need to explain why this young and charismatic guy is now the Chief Scientist at Salesforce. His recent contribution to the Natural Language Processing community has been outstanding during the last few years. In his talk he gave a comprehensive view of recent advances in NLP but most importantly a few ideas on how to tackle important problems like:
- Long-term memory (via Dynamic Memory Networks).
- Question representations contextualization (via Dynamic Co-attention Networks).
- Make RNNs faster (via Quasi-Recurrent Neural Networks)
- Long sequence generation (via Deep Reinforced Models)
- Greater generalization capability (via Joint Many-Task Models)
But what I liked most, was his idea of using Query Answering as a comprehensive framework for evaluating deepNLP techniques, which, if you think about it, can comprehend most of the other language related sub-tasks like summarization, sentence generation, POS tagging, etc…
Marc’Aurelio Ranzato — “Learning Representations for Vision, Speech and Text Processing Applications”
One of the lecture series I enjoyed the most was from Marc’Aurelio Ranzato, a giant in the Deep Learning and Computer Vision community and now a research scientist at Facebook FAIR.
He’s really a great teacher with clear explanations, simple examples and useful tips. It was really a pleasure to get back to the basics with him and listening to his tips and advices.
Moreover, he was the only lecturer (from what I know) who actually has shown some practical examples in PyTorch and interesting demos along the lectures.
Finally, within his third lecture he landed on more cutting-edge architectures and complex tasks involving sequential data. I really enjoyed his ability to rationalize and put together the huge quantity of architectures, visions and approaches in this context!

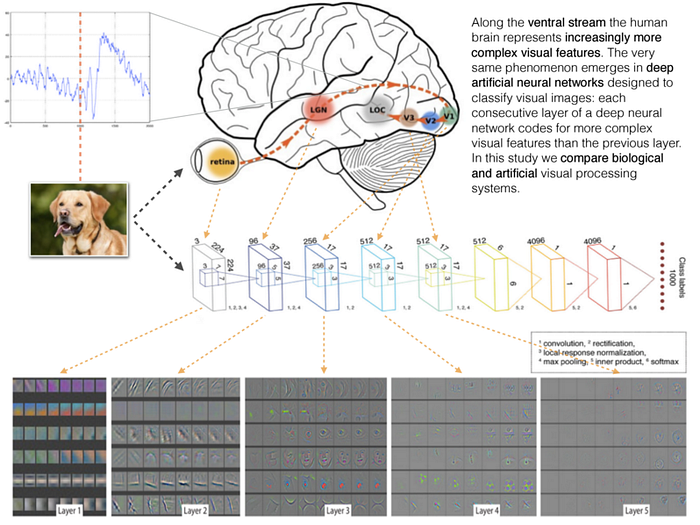
Maximilian Riesenhuber — “Deep Learning in the Brain”
Woah guys, this was really a big deal. Maximiliann Riesenhuber is an exceptionally smart and talented Computational Neuroscience researcher whose early works with Tommaso Poggio and others on the HMAX model was essential for the great advances in Deep Learning we witness today.
His course was absolutely fascinating. He started presenting the basic visual processing which happens into the brain: through feed-forward, “simple-to-complex” hierarchies. Then he moved to more recent insights on how deep hierarchies in the brain are structured and a few hints on re-entrant signal for learning and conscious awareness.
The third and more interesting lecture was about learning across different modalities: from objects to words, audition, and touch.
For me it has been a great source of inspiration, even tough it seems we are still far away from understanding how learning actually works inside the brain.
Indeed, we’ve pretty figured out how the raw input signals are processed throughout more and more abstract hierarchical representations… but we have no ideas on how these hierarchies can be actually build (i.e. learned)!
The fact is that with non-invasive techniques like MRI, fRMI and EEG the resolution is still too low to actually make sense of this complex, messy and parallel machine like the brain (even though we are making exponential progresses in brain scanning tools).
Richard Zemel — “Learning to Understand Images and Text”
Fresh new Research director and Co-founder of the new Vector Institute for Artificial Intelligence and Professor of Computer Science at the University of Toronto, Richard Zemel is not the kind of guy you want to miss. His course was split on three main lectures:
- Recent advances in CNNs
- Few shots learning
- Generative models for images and Text
Few shots learning is one of the few tasks in which Deep neural Networks still strive to compete with humans. It seems like the progresses in this area are moving pretty fast. Still, I do not believe that this is a major problem in Deep Learning. As humans we do not solve a task of recognizing a never-seen-before object with a single picture of it. Most of the time we use a lot of input modalities and even in a few seconds we are able to gather tons of information (around 400 billion bits per second).
The third lecture was pretty interesting too. He underlined the importance of predicting context for tackling Unsupervised learning and being able to generate content. His recent contributions on both Images and Text (or in complex multimodal scenarios) are amazing!
Michael C. Mozer — “Incorporating Domain Bias into Neural Networks”
Despite the long days zapping through lectures I also managed to have a grasp of the Michael Mozer’s lectures, ex Hinton post-doc and now Professor in the Department of Computer Science and the Institute of Cognitive Science @ University of Colorado Boulder, he takes the stand with a very practical view on the use of Deep Learning, writing in is course description:
“Deep learning is often pitched as a general, universal solution to AI. […] Although this fantasy holds true in the limit of infinite data and infinite computing cycles, bounds on either often make the promise of deep learning hollow. To overcome limitations of data and computing, an alternative is to customize models to characteristics of the domain.”
Despite I’m more the dream-10-years-in-the-future guy I can see his point, especially for practical implementations and real enterprise solutions. Moreover he talks at lengths on how to actually incorporate diverse forms of domain knowledge into a model via its representations, architecture, loss function, and data transformations (or, why not, their combination!).
He also talked about his recent work on a new kind of Recurrent Neural Networks (Discrete-Event Continuous-Time Recurrent Nets) which can embed an take also the timing of the events into account (not just their sequentiality). It turns out that feeding the time in which an event occurred along with the actual input to an LSTM can achieve the same accuracy (lol). Still, I really liked his approach which seems to be also the way in which humans handle memories of past events (to some extent [4][5]).
George Cybenko — “Deep Learning of Behaviors”
Unfortunately, I didn’t have the time to fit Cybenko’s lectures into my tight schedule. Still, I had the chance to see Li Deng pushing him to talk about his famous “Universal Approximation Theorem” (this was real fun lol), which by the words of the same Li was maybe one of the main reasons why depth in neural networks was not explored much back in the 80s’ hence leading to a substantial delay in the explosion of Deep Learning.
When pushed even harder to get his thoughts on why deep models works better than shallow ones, as a real mathematician he just said he got boring soon after the 1-year spent on that demonstration and suddenly took another direction. Since then, he explicitly said he’s not given a lot of thoughts about that!

Open and industrial session
During the week I soon realized a large chunk of the people attending the school was coming from the Industry. It was amazing to see such involvement and get in touch with so many industrial realities.
As a PhD student it was also very nice to have the possibility to speak in front of so many people talking about our latest research effort CORe50, a new dataset and benchmark for Continuous Object Recognition. Take a look at it if you want to learn more about my research activity! :-)

Final remarks
During my stay I’ve also had the chance to know many people from around the world sharing my passion towards Deep Learning and Artificial Intelligence. I’m so glad to be part of this huge family of smart people pushing the limits of machine and human intelligence! :-)

If you want to get in touch or you just want to know more about me, visit my website vincenzolomonaco.com or leave a comment below! :-)
